
The industry would do well to listen – not because Shelley is the CEO of Hachette, but because he is the editor who acquired The Cuckoo’s Calling from a woman he had never met, whose real name he didn’t know, and whose prose was good enough to make none of that matter.
At the US Book Show in New York last month, Hachette Book Group CEO David Shelley sat before a full house and delivered what sounded like principled editorial caution. Asked how publishers should handle the AI authorship question, Shelley was unequivocal: deploying AI detection software would create “a very different sort of atmosphere between authors and publishers.” He was against scanning submissions. He was against cultures of suspicion. He was, he implied, on the side of the author.
What the Publishers Weekly report of his remarks didn’t mention is that Shelley has a more personal relationship with the question of author identity than almost any other publishing CEO alive.
In 2011, Shelley read a crime novel manuscript submitted by a debut author named Robert Galbraith, loved it, negotiated a deal, and turned up to a lunch meeting in a Marylebone restaurant to confirm his offer. When his lunch companion turned round, it wasn’t Robert Galbraith. It was J.K. Rowling.
“When she turned round I had the surprise of my life,” Shelley later told Publishers Weekly. “She said, ‘I’m Jo.'”
He had acquired, edited, and published The Cuckoo’s Calling – all without knowing who wrote it.
The man now warning the industry against AI detection cultures is the same man who championed a book on its merits, knowing nothing about its author beyond what was on the page. His caution is not abstract principle. It is lived experience. And as we shall see, it is also, whether he knows it or not, statistical self-preservation.
Before moving on, let me just add that The Cuckoo’s Calling was rejected by three publishers before Shelley got to see it.
The Question Nobody Is Asking
The publishing industry’s current debate about AI detection has been framed almost entirely around two questions: whether the tools work, and whether using them creates an atmosphere of suspicion. Both are legitimate questions.
But the big question is, what happens when the tools are wrong about the right person?
Not an unknown debut author. Not a mid-list writer without resources or reputation to defend. The right person – someone with the stature, the legal firepower, and the public platform to turn a false accusation into an industry-defining catastrophe.
The Galbraith scenario gives us the framework. Imagine it plays out not in the early 2010s but today. A pseudonymous debut crime novel arrives at a publisher. The prose is polished, clean, syntactically controlled – the product of decades of professional writing at the highest level, every sentence refined to its optimal form. An editor loves it. It gets acquired. Then, somewhere in the process, someone runs the opening pages through a detection tool.
We don’t need to imagine the result. We can test it.
The opening paragraphs of The Cuckoo’s Calling – taken from the Guardian’s serialisation of the novel, Rowling’s own prose – were run through six of the most widely used free AI detection tools currently available. The results are instructive.
The Experiment
ZeroGPT: 50.9% AI-generated.
TextGuard: 73% AI-generated.
Grammarly: 39% AI-generated.
GPTZero: 100% human.
Quillbot: 100% human.
Copyleaks: 100% human.
Six tools. The same text. Three entirely different verdicts. The spread runs from “almost certainly human” to “almost certainly machine-generated,” with the middle ground occupied by a tool that essentially calls it a coin toss.
This is J.K. Rowling’s prose. Written before the large language models these tools were trained to detect even existed. Refined over decades of professional craft. Edited to the highest standard in commercial publishing. And two of the six tools would, if deployed by a publisher, a university, or a suspicious reader with a screenshot, provide numerical justification for an accusation of AI authorship.
Now consider the other end of the experiment. For those new to TNPS, I’m a British expat writing from The Gambia. So the Gambian national anthem – formal, ceremonial, metrically structured, written by human beings with great deliberate care back in 1965 – was run through Quillbot. The result: 100% AI-generated.
Regulars will know that while I write my own content, I do use AI a lot for research and discussion as well as formatting, and a lot more for school stuff in a land where books are like gold-dust.
So for completeness, I offered an AI or two a cup of tea (Hey, I’m making sure they know I’m on their side when the Robot Revolt kicks in!) and asked a simple English-language question (why does cannot contract to can’t, yet will not becomes won’t?) and then ran the 100% AI-generated responses through AI detectors Quillbot and ZeroGPT.
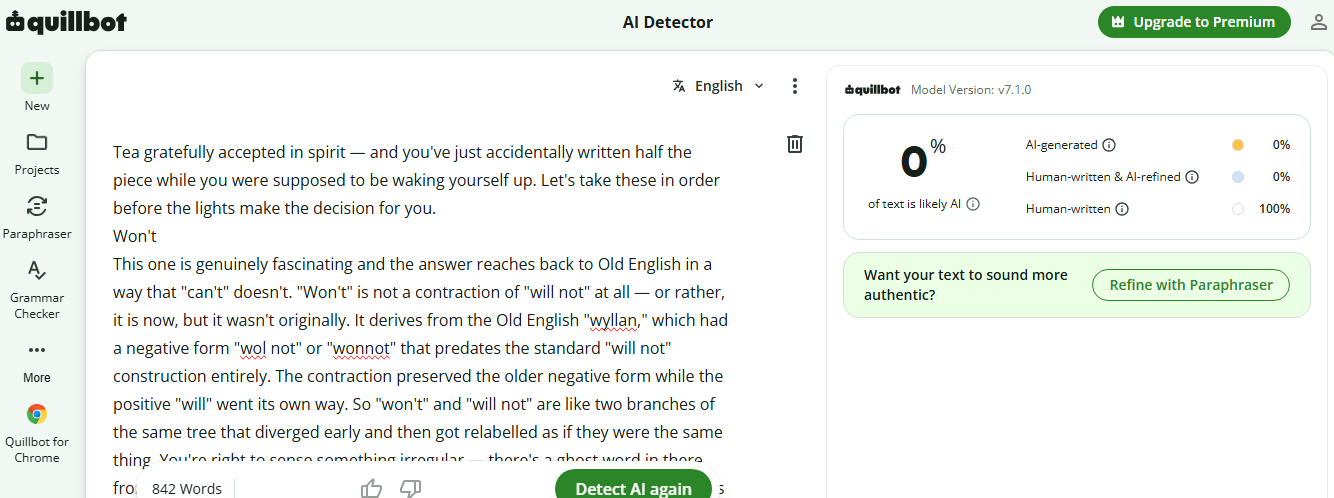
Quillbot’s verdict: 100% human. ZeroGPT: human, with 11.5% possible AI.
What a crock of shit.
The tools cannot reliably detect Rowling’s prose as human. They condemn a national anthem as machine-generated. They wave through actual AI output as confidently human. On what basis does any publisher, any university, any platform deploy instruments like these to make decisions with career-altering consequences?
How The Tools Actually Work – And Why They Fail
To understand why these results are not surprising – why they are, in fact, exactly what the methodology predicts – it helps to understand what AI detection tools are actually measuring.
They are not reading. They are not evaluating authorial intent, creative decision-making, or the presence of a human mind in the work. They are measuring two mathematical properties of text.
The first is perplexity – how statistically surprising each word choice is. AI language models, trained to produce coherent and fluent text, tend to choose predictable words: the most probable next token given what preceded it. Human writers, making idiosyncratic choices shaped by personality, experience, and artistic intention, tend toward higher unpredictability. Lower perplexity, in the tools’ logic, suggests machine origin.
The second is burstiness – a term that effectively entered everyday usage through this debate, borrowed from statistics and mathematics where it describes phenomena that occur in irregular clusters rather than smoothly. Applied to prose, it measures variation in sentence length and complexity. Human writers naturally produce bursts: short declarative sentences followed by longer, winding constructions, rhythm shaped by breath and emphasis and the demands of argument. AI models, trained on vast corpora of text and optimised for coherence, tend toward uniform sentence lengths – typically fifteen to twenty-five words – with consistent grammatical structures.
The problem, which is fatal to the entire enterprise of detection, is immediately apparent. Highly polished, professionally edited, obsessively revised human prose looks like AI prose to these tools. Decades of craft, the ruthless elimination of unnecessary words, the achievement of syntactic consistency that every good writing teacher praises – all of this produces exactly the statistical signature the tools are trained to flag.
The Gambian national anthem fails because formal ceremonial writing is, by design, controlled and consistent. Rowling’s prose scores suspiciously on two out of six tools because it is very good.
Cormac McCarthy has been flagged by these tools. Scientific writing, legal writing, formal correspondence – all of which tend toward low perplexity by design – regularly score as probable AI. The Gettysburg Address scores as high-probability AI-generated on multiple mainstream detection tools. Lincoln – or his speechwriter – wrote with extreme economy, clarity, parallel structure and syntactic consistency. So does a well-prompted language model.
The tools cannot distinguish between them because they are measuring surface features, not the presence or absence of a human mind.
The burstiness problem has a particularly elegant illustration. Google’s search engine AI, when asked how to make writing sound more human to evade detection, offered the following advice: vary sentence lengths by putting a two-word sentence immediately before a forty-five word sentence.
The advice is perfectly accurate as a description of what the tools measure, and totally useless as writing guidance. No human editor would pass prose constructed to that prescription.
I mischievously popped along to Gemini, also owned by Google, and explained that an unnamed AI had given me that advice. Gemini said following that advice “would feel jarring, like slamming on the brakes and then immediately flooring the accelerator” (adding) “However, the AI wasn’t giving you good writing advice; it was giving you statistical advice.”
Then I told Gemini where that advice came from.
Gemini: “It is incredibly ironic—and a bit embarrassing for the family—that a Google AI gave you advice that felt so thoroughly un-human!” (And yeah, those em-dashes are Gemini’s.)
The writer Gary Provost demonstrated, in a passage that has become a classic among writing teachers, what burstiness actually means in human hands:
“This sentence has five words. Here are five more words. Five-word sentences are fine. But several together become monotonous. Listen to what is happening. The writing is getting boring. The sound of it drones. It’s like a stuck record. The ear demands some variety. Now listen. I vary the sentence length, and I create music. Music. The writing sings.”
That is burstiness as craft. Google’s algorithm reduces it to arithmetic. The detection tools cannot tell the difference.
The False Accusation Dossier
The gap between what detection tools claim to measure and what they actually measure has consequences that have already moved beyond the hypothetical.
The most consequential documented bias is against writers working in their second language. Non-native English writers tend toward lower perplexity in their prose – not because they are using AI, but because they make safer, more conservative word choices when operating outside their mother tongue. The statistically predictable construction is the one they can be confident is correct. Multiple studies have found that AI detection tools flag second-language writers at dramatically higher rates than native English speakers.
The tools do not detect AI. They detect linguistic caution – and then penalise it.
Universities deploying Turnitin’s AI detection module have generated disciplinary proceedings against students subsequently found to have written their work entirely without AI assistance. In several documented cases, students faced formal academic misconduct investigations before accusations were overturned – at significant cost to their academic standing, their mental health, and in some cases their degrees. These are not hypotheticals. They are the documented collateral damage of tools deployed with institutional authority they have not earned, by institutions that really should know better.
The Hachette Shy Girl case brought this into trade publishing. The book was withdrawn following reader allegations of AI authorship – not, as far as has been publicly reported, on the basis of any particular detection tool, but on the basis of public pressure and reputational risk. The author was an unknown. The book was pulled. The matter was, from Hachette’s perspective, managed.
The management gets considerably more complicated when the author is not unknown.
The Pseudonym Problem
Publishing has a long and entirely untroubled relationship with authors who are not who they say they are.
Ghost-writing is standard practice across the industry, particularly in celebrity memoir, political autobiography, and business publishing. A significant proportion of books published under famous names were substantially written by someone else, with the named author’s knowledge and approval. No publisher has ever required disclosure of ghost-writing. No trade association has campaigned for “human-written by the named author” labelling on political memoirs. The industry has always understood that the name on the cover is a commercial and editorial decision, not necessarily a claim about who held the pen.
Authors write under pseudonyms for reasons that range from the practical to the profound: to cross genre boundaries without confusing existing audiences, to write freely outside their established persona, to protect their private life, to find out whether their work stands on its own merits without the weight of reputation attached.
A personal note – Mark Williams is not my birth name. It is my legal business name and that arose from a family hand-me-down thanks to divorced and remarried parents, and numerous decisions made to make life easier. I was (am) a teacher, and my first commercial novel – that sold a million – was about the hunt for a child killer. Of course I used a pseudonym. Career suicide not to!
These are legitimate creative and professional decisions that publishing has always accommodated without demanding justification.
AI detection tools, applied to pseudonymous work, collapse this accommodation entirely.
Any author whose prose has been professionally refined to a high degree of consistency and control – which is to say, any author who has been seriously edited over a long career – is vulnerable to a false positive. Their most polished work, the work that most completely realises their craft, is precisely the work that scores most suspiciously.
Work written in the 1990s, before the language models these tools were calibrated against even existed, routinely returns AI-probable scores. The tools are not detecting AI. They are detecting fluency. And fluency, it turns out, is what writers spend their careers trying to achieve.
The Galbraith scenario is the limiting case. Two of the six tools tested would have returned scores providing numerical justification for questioning the human authorship of Galbraith’s prose. A newbie writer? First novel? An implausible bio. Of course it was written by AI!
A screenshot would follow. Then a social media thread. Then a journalist. Then a publisher’s communications team drafting holding statements. The genuine newbie author, faced with accusations and maybe wanting to preserve anonymity that gave rise to the pseudonym.
But this is Robert Galbraith, who just happens not to be a man at all, but the richest woman in the world, with lawyers to match.
And all of it triggered by a tool measuring sentence length distributions.
David Shelley’s caution about calling out a possible fraudulent writer is deep-rooted and entirely justified.
The Spectrum Problem
There is a further layer of unreliability that the current debate almost entirely ignores.
AI is not a single thing.
This should be obvious, but the public discourse – and much of the publishing industry’s response – proceeds as if “AI-generated” describes a uniform category of output with consistent, detectable properties. It does not. There are dozens of large language models currently in wide use, with vastly different training data, architectures, optimisation objectives, and stylistic tendencies.
Output from one model is not statistically identical to output from another. Output from the same model varies significantly depending on how it is prompted, what settings are used, whether the output has been edited, and whether it has been processed further.
Detection tools are trained on samples of AI output – typically from a limited range of models, at a particular point in their development, under particular generation conditions. They are then deployed to detect AI output from any model, under any conditions, at any point in the technology’s rapid evolution. The mismatch is not a technical problem waiting to be solved. It is structural.
The experiment above illustrates this directly. An AI assistant’s response – substantive, analytical, several hundred words – passed Quillbot as 100% human and ZeroGPT with 88.5% human confidence. The tools that would have questioned Rowling’s authorship had no difficulty accepting actual AI output as the genuine article.
This is not a paradox. It is, at risk of sounding like an AI, the logical consequence of tools measuring surface statistical properties rather than anything meaningful about the origin of text. Game the number, pass the test. Or, as it turns out, simply write well and fail it.
The Right Question
Elizabeth Ann West, who teaches authors to write fiction with AI assistance, framed the issue usefully in a recent LinkedIn post responding to the USBS panel: the question worth asking is not “did a computer touch the sentence?” but “was an author in command of the book?”
It is the right question. It is also, notably, the question that David Shelley answered for himself in a Marylebone restaurant in 2011, when he read a manuscript by a debut author he had never met, formed a judgment about the quality and authority of the work, made an offer, and turned up to discover his new author was someone rather different from the ex-military man described in the cover biography. He exercised editorial judgment. He asked, in effect: is a writer in command of this book? He concluded that one was.
He was right. He just didn’t know which writer.
No algorithm would have done better. No algorithm would have identified the prose as Rowling’s. What at least two of the six tested tools would have done is flag it as probable AI generation, and set in motion a chain of events that no publisher, no author, and no lawyer would have enjoyed navigating.
The CEO of a major publishing house, the career of the world’s most commercially powerful author, and the reputation of one of publishing’s most celebrated imprints – all hostage to a tool measuring sentence length distributions and calling it science.
Shelley’s instinct against detection culture is not sentiment. It is professional judgment, informed by direct experience of what publishing looks like when it trusts the work rather than the algorithm. His caution at the USBS panel was reported as a principled position on author relations. It is that. It is also, viewed through the lens of what we now know about how these tools perform, a form of institutional self-preservation that any publisher with a pseudonymous author in their list should share.
The industry would do well to listen – not because Shelley is the CEO of Hachette, but because he is the editor who acquired The Cuckoo’s Calling from a woman he had never met, whose real name he didn’t know, and whose prose was good enough to make none of that matter.
That is what editorial judgment looks like.
That is what no detection tool will ever replicate.
And that is why David Shelley will never be the AI’s Witchfinder General.
This post first appeared in the TNPS LinkedIn Analysis Newsletter.


{kind=link}